GET CLEAN. BE READY. PERFORM BETTER.
The Bullhorn data solution that drives confident performance.
Data touches every part of the recruitment journey - sourcing, outreach, reporting, AI.
Clean keeps it accurate, visible, and AI-ready, with deduplication, analytics, and automated routines.
It doesn't look like a data problem to your clients, candidates, and leadership team. It just looks like disorganization, slow sourcing, or campaigns that underperform.
Your data looks fine from the outside. But staffing databases accumulate problems that you can’t always see, and for the stuff that you can, people develop workarounds (that cost you time and money, and are usually flawed).
The moment you layer AI or automation on top of it, the scale of the problem multiplies. These tools don't fix bad data. They inherit it, and execute on it faster.
Data quality isn't a hygiene task. It's a performance problem.
THE TERRAIN
The problems in your staffing database are already everywhere. They're just hard to see.





Duplicate records clutter every search
Recruiters piece together notes, numbers, and resumes across three versions of the same person.
Reports contradict each other
Pipeline-by-source never matches week to week. Forecasting becomes guesswork.
Automation misfires at scale
Nurture sequences hit both records. Unsubscribes spike. Deliverability suffers.
AI amplifies the problem
AI surfaces a candidate already placed - flagged 'available' on a duplicate.
Compliance gaps go unnoticed
An opt-out on one record doesn't catch the duplicate. Someone who asked not to be contacted still gets reached.
Feel familiar? Find out whats in your database.
You’re looking at the symptoms. Your data is the cause.
The Clean Data Diagnostic tells you exactly what shape your data is in, and what to do about it.
The complete Bullhorn data performance system.
WHAT CLEAN DOES
O3
Clean Duplicates
Advanced duplicate merging.
Clean Duplicates takes staffing specific logic into account and understands nuances that other solutions often miss.
The result is merging that's confident, safe, and built to handle complexity.
O1
Clean Analytics
Visibility that drives your next decision.
You can't improve what you can't measure.
Clean Analytics gives you a real-time picture of your database health, where problems are coming from, and whether things are getting better.
O2
Clean Routines
Automated clean ups that keep your data in shape.
Cleaning data manually, or as a one-off exercise, is how you end up back where you started.
Routines are scheduled automations that catch and fix issues before they build up. Set the conditions once. Clean handles it from there.
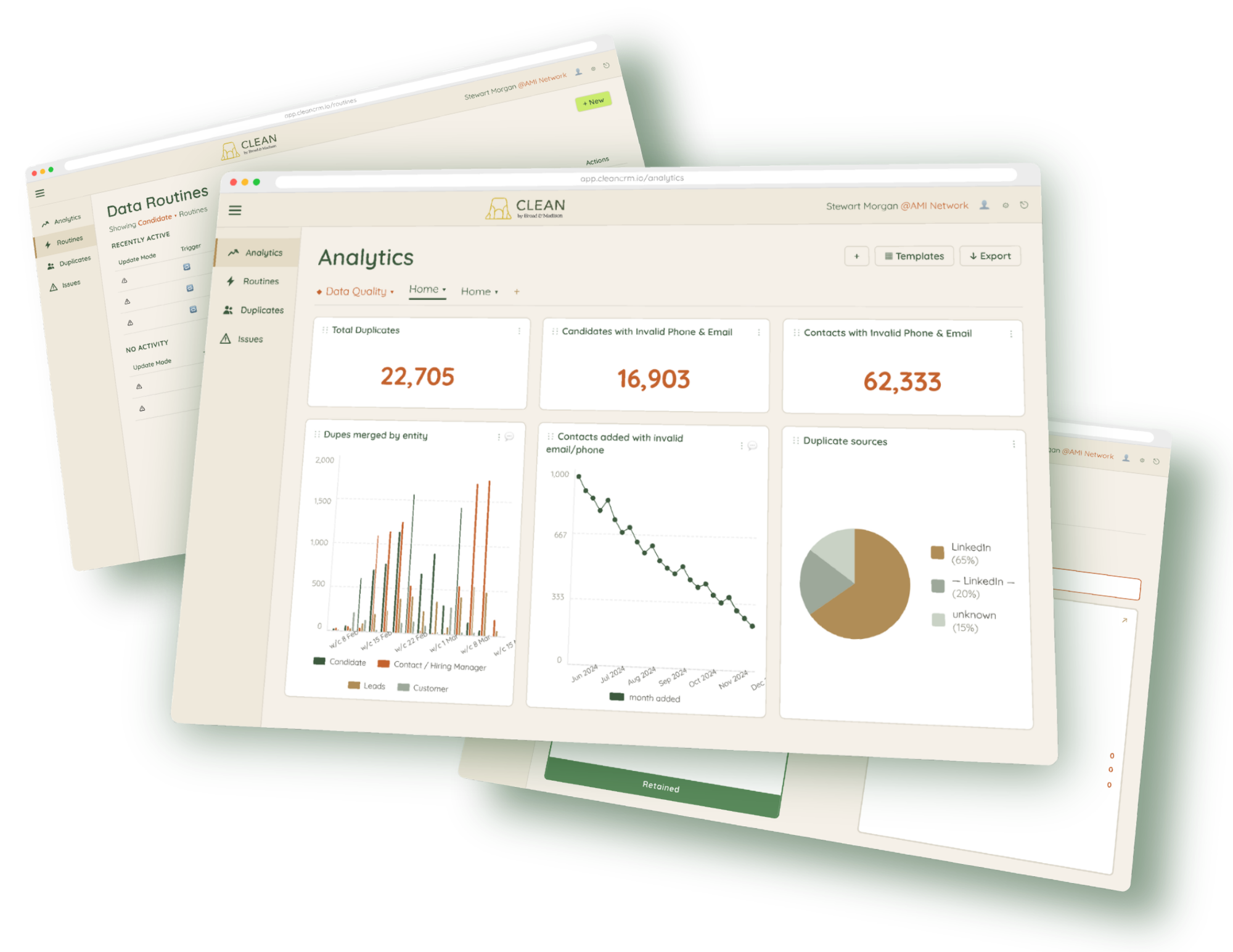
CLEAN ANALYTICS
Understand what’s in your database and what needs attention.
Staffing databases carry years of accumulated problems. Inaccurate data erodes confidence, and when you can't trust it, you stop moving with conviction. Decisions get made on instinct rather than information.
Clean changes that by giving you full visibility into your database health - how many records are actually contactable, where duplicates are inflating your numbers, and whether things are improving over time.
Insights that drive long-term data health:
✓ Quick glance database health dashboard
✓ Duplicate analytics by source (LinkedIn, Indeed, manual entry, job boards)
✓ Contactability reporting, invalid and missing emails and phone numbers
✓ Field completeness tracking
✓ Trend monitoring over time, duplicates added vs. merged, progress over weeks and months
 Stewart Morgan @Company Name
Stewart Morgan @Company Name
Analytics
◆ Data Quality · Home · Home · +
CLEAN ROUTINES
Keep data accurate, complete, and ready.
Clean's automations handle the everyday data quality issues that slip through. Formatting errors, stale status flags, invalid contacts, inconsistently coded fields. These run on a configurable schedule, overnight, midday, or on demand, so your data stays clean.
Automated data fixes, including:
✓ Field normalization
✓ Formatting and punctuation fixes
✓ Invalid email and phone detection
✓ Candidate status updates and cleanup
✓ Standardized field values and status codes across your database
✓ Configurable rules and triggers that allow you to setup your own routines
Stewart Morgan @Company Name
Data Routines
Showing Candidate ▾ Routines
CLEAN DUPLICATES
Merge duplicates safely and at scale.
Find and merge duplicate Candidates, Contacts, Companies, and Leads across your ATS or CRM. Built-in guardrails, configurable confidence thresholds, and one-click undo keep the process safe and controlled, even across large, complex databases.
Advanced deduping for staffing ATS / CRM:
✓ Candidate, Contact, Company, and Leads deduplication
✓ Recruitment-specific matching logic
✓ Confidence thresholds and exclude toggles
✓ Bulk and field-level precision merging
✓ Instant undo / merge reversal
✓ Merge notifications for record owners
✓ Social profile matching (LinkedIn, Indeed)
✓ Parent/child company linking
Stewart Morgan @Company Name
Duplicates
▸ Showing 9 of 435 All Duplicates ▾
★ Strong match · 0 pts Found: 2 months ago
THE AI DILEMMA
AI is only as good as the data it runs on.
45% of companies cite data as the primary barrier to AI adoption, according to Bullhorn's 2026 GRID Industry Trends Report.
Bad data doesn't slow AI down
It gets amplified and executes on it faster. Duplicate sourcing at AI speed means more duplicate outreach, faster. Stale records get surfaced as active. An opt-out on one record doesn't catch the duplicate.
Clean maps the data underneath before AI fires.
Deduplication, field normalization, and automated routines run before AI touches your data.
Your AI investment works when your data does
Better data in. Better AI performance out. When records are accurate, complete, and consistently formatted, and the ROI AI promises is the ROI you get.
WHO CLEAN IS FOR
Feel the benefits across your business
Leadership
"I asked for conversion rate by source. Three people gave me three different numbers. We made a headcount decision based on one of them."
THE PAIN
Decisions made on data that can't be trusted. An inflated pipeline. AI and automation that aren't delivering what was promised.
WHAT CHANGES
One version of the truth. Reports that reconcile. Headcount and investment decisions made on data that leadership can defend.
Recruiter
"I’d rather search LinkedIn than our own database. At least I know those results are real."
THE PAIN
The database has let them down often enough that going elsewhere feels faster. Duplicate records, incomplete profiles, contact details that lead nowhere. Every bad search makes LinkedIn feel like the only route.
WHAT CHANGES
One complete result per candidate. The CRM becomes worth using. More time on revenue-generating work, less on reconciling records.
Ops / CRM Lead
"I spend more time explaining why the data is wrong than I do actually using it. Every workflow has a workaround."
THE PAIN
Automations break on bad data. No visibility into where duplicates originate. Constant reactive firefighting.
WHAT CHANGES
A tech stack that runs as it's supposed to. Source-level visibility on incoming duplicates. Time to build, not fix.
Marketing
"We sent a nurture campaign and three people replied saying they’d received it twice. One unsubscribed."
THE PAIN
Duplicate outreach damages brand reputation. Consent is fragmented across records. Automation misfires at scale.
WHAT CHANGES
Campaigns that land once, correctly. Consent follows the record through every merge — compliance managed continuously, not surfaced as an incident. Deliverability and engagement hold up because sequences aren't firing to fragmented or invalid records.
THE BUSINESS IMPACTS
Data that drives confident performance

CRM adoption improves
Recruiters trust the database and stop defaulting to LinkedIn. It becomes their first stop.
Reporting becomes reliable
One version of the numbers. Forecasts hold up. Board presentations stop needing manual reconciliation.
Automation fires correctly
Sequences hit one record, not two. Deliverability and engagement rates hold up over time.
AI performs at its stated ROI
Amplify and other AI tools work from data that reflects reality, matching accuracy improves, submission rates follow.
Sourcing gets faster
One complete result per search. No time spent piecing together which version of a record is current.

Compliance risk reduces
Opt-outs are consolidated across merged records. AI-driven outreach can't reach someone who asked not to be contacted.

Client and candidate experience improves
Every interaction feels considered. Not duplicated, not confusing, just professional.
Ops teams stop firefighting
Automated routines handle issues before they stack up. Your team spends time building, not fixing.




FLEXIBLE PRICING
Start when you're ready, scale as you need.
Start for free
The Clean Data Diagnostic costs nothing. No contract, no payment details, no commitment.
See exactly what's in your database before deciding anything - move to Clean as you see value.
No contract lock-ins
No contract lock-ins. No implementation fees. No long onboarding process.
Clean is designed to prove its value quickly and earn ongoing commitment, not lock you into one.
No implementation fee
Clean implementations happen so fast that we'd be embarrassed to charge for it.
You're running Clean before most tools have finished their scoping calls.
WHAT SETS CLEAN APART
Anyone can build a data tool. Not everyone understands staffing.
Recruitment data has a context that generic tools don't account for. Knowing which record to trust, how to handle placement history, how parent and child companies relate, what a stale status flag actually means for a recruiter. That knowledge comes from years inside the industry.
Grounded in staffing expertise
Clean is built by people with experience specific to staffing technology.
That knowledge shapes how the product works, how it's implemented, and how it handles the situations that generic tools and internal builds struggle to anticipate.
Built for performance, not maintenance
The data-cleaning conversation in recruitment is stuck on yesterday's terrain.
With Clean, data quality is a strategic performance advantage. Not a chore. Not a one-time fix. A continuous foundation that makes everything else perform at its best.
Supporting long-term data health
Clean’s analytics allow you to solve the root cause, not just the symptom.
The result is a foundation you can build from - one that ensures your AI and automation, your reporting, and your teams perform at their best.
From Our Clients
-
![]()
“Clean gave us visibility into where most duplicates were originating, allowing us to address root causes and prevent the issue from continuing.”
-
![]()
“...we can now compare Clean to Batman... doing cleanup work silently, at night, and giving the people what they want."
-
![]()
“...as opportunities for automations and targeted outreach grew, we wanted greater confidence in the data underpinning them."
TAKE THE NEXT STEP
Get Clean.
Your data is either working for you, or against you. Find out where yours stands with the free data diagnostic, or book a demo of Clean today to learn how you can build a database that drives confident performance.
FAQs
Frequently asked questions
-
Staffing data hygiene is the ongoing practice of keeping ATS and CRM records accurate, complete, and free of duplicates.
It includes things like deduplication of candidates, contacts, companies, and leads, field normalization / standardization, invalid contact removal. It can be done as a one-off fix but it is recommended to setup automated routines that prevent problems from building back up after a cleanup.
Staffing firms accumulate database records from multiple sources (including LinkedIn, Indeed, job boards and manual entry) which can result in incomplete, duplicate and incorrect data. Data hygiene is what keeps the ATS / CRM database reliable enough to recruit from, report on, and run AI tools against.
-
Duplicate records are created when the same candidate , contact, company, or lead enters through multiple channels. Typical sources of duplicate ATS / CRM (including Bullhorn) records include LinkedIn application, job board integration such as Indeed, plus manual entry, each creates a separate record for the same entity.
Without automated deduplication, these records accumulate without anyone noticing. Across the databases we've assessed, 85%+ of duplicates originate from LinkedIn and job boards alone.
-
Bullhorn gives the ability to merge records manually but this doesn’t give the depth staffing firms typically need.
Clean integrates with Bullhorn to identify duplicate Candidates, Contacts, Companies, and Leads using staffing-specific matching logic. It accounts for name variations, social profile matches across LinkedIn and Indeed, and parent/child company relationships.
Duplicates are merged with configurable confidence thresholds, field-level precision controls, and instant undo, so nothing is lost in the process.
-
Yes, directly. Bullhorn Amplify works from the records in your Bullhorn database, and if those records contain dirty data such as duplicates, stale status flags, or incomplete profiles, the AI surfaces and acts on that information.
A candidate already placed can appear as available. A nurture sequence can fire to both a record and its duplicate.
45% of companies cite data as the primary barrier to AI adoption, according to Bullhorn's 2026 GRID Industry Trends Report. Clean is the foundation layer that ensures Bullhorn Amplify is working from data that reflects reality.
-
The Clean Data Diagnostic is a free database health assessment for Bullhorn and Vincere users. We analyze your database for duplicate records, invalid contacts, missing fields, and find where problems are originating. Then we'll provide a full report of issues and recommendations on how to clean your data up.
It's the starting point for understanding what's actually in your database before committing to any cleanup or hygiene solution.
-
A one-off cleanup gets your database to a better starting point, but without ongoing hygiene, new duplicates and data quality issues accumulate within weeks.
The answer isn't a quarterly cleanup schedule; it's continuous automated routines that catch and fix issues before they become a problem.
Clean runs on a configurable schedule, so your database stays healthy rather than degrading between manual exercises.
-
A one-off cleanup removes the backlog of problems that have built up, it's a starting point, not a long-term solution.
Broad & Madison focuses on long-term data health. Ongoing data hygiene combines that initial cleanup with automated routines that run continuously, preventing the backlog from returning.